Save Python Pivot Table in Excel Sheets ExcelWriter
Untitled
This is a quick script on how to save Python pivot_table in an excel file.
Credit to pbpython
In [1]:
|
1 2 3 4 |
import sqlalchemy import pyodbc from pandas import DataFrame import pandas as pd |
In [2]:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
df = DataFrame ## connect to SqlServer Database and get information. try: import urllib params = urllib.quote_plus("DRIVER={SQL Server Native Client 11.0};SERVER=.\MSSQLSERVER_ENT;DATABASE=Antrak;Trusted_Connection=yes;") engine = sqlalchemy.create_engine('mssql+pyodbc:///?odbc_connect=%s"' % params) resoverall = engine.execute("SELECT * FROM FlightBookingsMain") df = df(resoverall.fetchall()) df.columns = resoverall.keys() except (RuntimeError, TypeError, NameError): print('Error in Conneccting') print(RuntimeError, TypeError, NameError) finally: print("connected") |
In [8]:
|
1 |
df.head() |
Out[8]:
In [9]:
|
1 2 |
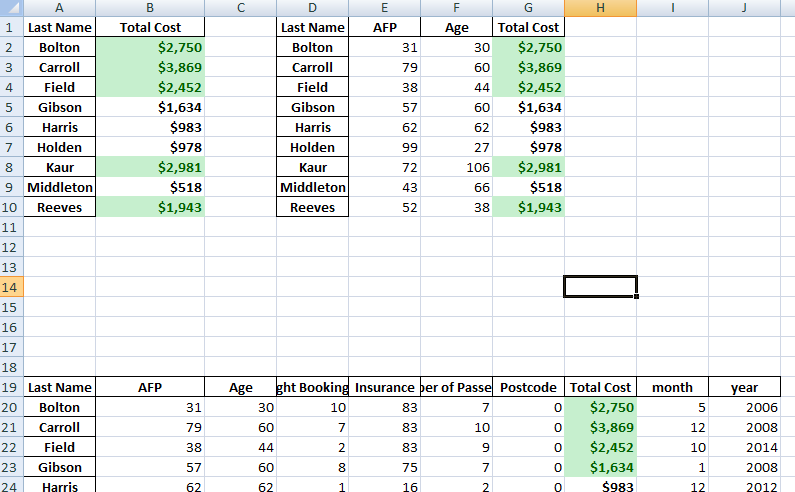
table = pd.pivot_table(df, index=['Flight Name','First Name','Email Address'], values=['AFP', 'Age','Total Cost'], aggfunc = np.sum) table |
Out[9]:
In [10]:
|
1 |
table.xs('ZWD', level=0) |
Out[10]:
In [ ]:
|
1 |
#lets create excel sheet for each flight name |
In [12]:
|
1 2 3 4 5 6 7 |
writer = pd.ExcelWriter('flightGrouping.xlsx') for flight in table.index.get_level_values(0).unique(): temp_df = table.xs(flight, level=0) temp_df.to_excel(writer,manager) writer.save() |
In [ ]:
Want more information like this?
People Who Read The Above Post Also Read This:
 Python Pandas Pivot Table Index location Percentage calculation on Two columns
Python Pandas Pivot Table Index location Percentage calculation on Two columns
 Python Pandas Pivot Table Index location Percentage calculation on Two columns – XlsxWriter pt2
Save Multiple Pandas DataFrames to One Single Excel Sheet Side by Side or Dowwards – XlsxWriter
Python Bokeh plotting Data Exploration Visualization And Pivot Tables Analysis
Python Pandas Pivot Table Index location Percentage calculation on Two columns – XlsxWriter pt2
Save Multiple Pandas DataFrames to One Single Excel Sheet Side by Side or Dowwards – XlsxWriter
Python Bokeh plotting Data Exploration Visualization And Pivot Tables Analysis