Machine Learning Hypothesis function Cost function and Gradient Descent Algorithm Short Notes
This is a short scrap notes from the Machine Learning Course taught by Associate Professor, Andrew Ng, Stanford University on Coursera.
hypothesis = hØ(x) + Øo + Ø1X
Parameters = Øo , Ø1
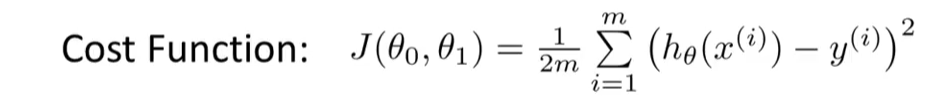
Our Goal = minimise Ø0 , Ø1 that is the cost function J(Ø0, Ø1)
GRADIENT Descent. An algorithm wich minimises the cost function , J that J(Ø0, Ø1)
Gradient descent is also a more general algorithm for general functions

The α, which is the learning rate in gradient descent controls how big a step we take in updating our parameters Øj
Local minimum is when our derivate term is equal to zero
As we approach local minimum , gradient descent will automatically take smaller steps. So no need to decrease α over time
In machine learning , Gradient descent is normally called “Batch Gradient Descent” meaning each step of gradient descent uses all
the training examples