Python Pandas Pivot Table Index location Percentage calculation on Two columns
pivot table for year on year
This is a quick example of how to use pivot_table, to calculate year on year percentage sales .
In [162]:
|
1 2 3 4 5 6 |
import sqlalchemy import pyodbc import numpy as np from pandas import DataFrame from bokeh.plotting import figure, output_file, show import pandas as pd |
In [163]:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
df = DataFrame ## connect to SqlServer Database and get information. try: import urllib params = urllib.quote_plus("DRIVER={SQL Server Native Client 11.0};SERVER=.\MSSQLSERVER_ENT;DATABASE=Antrak;Trusted_Connection=yes;") engine = sqlalchemy.create_engine('mssql+pyodbc:///?odbc_connect=%s"' % params) resoverall = engine.execute("SELECT * FROM FlightBookingsMain") df = df(resoverall.fetchall()) df.columns = resoverall.keys() except (RuntimeError, TypeError, NameError): print('Error in Conneccting') print(RuntimeError, TypeError, NameError) finally: print("connected") |
In [164]:
|
1 2 |
#lets check the head df.head() |
Out[164]:
In [165]:
|
1 2 |
#check lenght of data frame len(df) |
Out[165]:
In [166]:
|
1 2 3 4 5 6 7 8 |
# let get a start date we will read our data from from datetime import datetime date1 = datetime.strptime('30-01-16', '%d-%m-%y').date() date2 = datetime.strptime('30-01-17', '%d-%m-%y').date() date3 = datetime.strptime('01-02-16', '%d-%m-%y').date() #2016-02-01 date1 #date2 |
Out[166]:
In [167]:
|
1 2 3 |
#lets get the data from 30th January 1999 to 30th January 2018 year_subset = df.loc[(df['Booking Date']> date1) & (df['Booking Date']< date2)] #year_subset = df.loc[(df['Booking Date']> date1)] |
In [168]:
|
1 |
year_subset.head() |
Out[168]:
In [169]:
|
1 2 3 4 5 |
#lets change some values in the age column to zero. #lets change all the Age values on 2nd February 2016 to zero year_subset.ix[year_subset['Booking Date']==date3,'Age'] =0 |
In [170]:
|
1 2 |
#lets check if we have got some zero in our AGE column year_subset[year_subset['Age']==0].head(3) |
Out[170]:
In [171]:
|
1 2 3 4 5 6 7 8 9 10 |
#lets define a function to calculate the year on year from two columns def get_change(current, previous): #if current == previous: #return 0.0 try: return (current - previous)/previous*100.0 except ZeroDivisionError: print('error!!') return 0 |
In [172]:
|
1 2 3 4 |
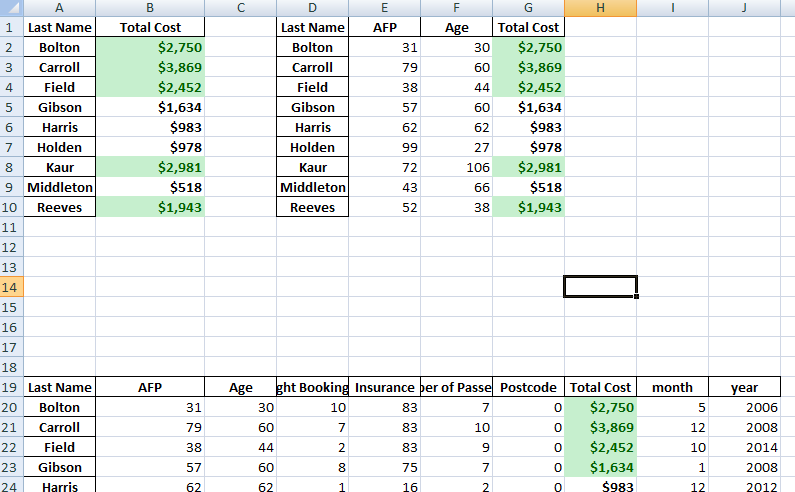
##lets get the Age and AFP columns with a sum gettable = pd.pivot_table(year_subset, index=['Booking Date'], values=['AFP', 'Age'], aggfunc = np.sum) gettable |
Out[172]:
In [173]:
|
1 2 |
#lets check some data gettable.ix[: , 1:2] |
Out[173]:
In [174]:
|
1 2 |
#lets run the function by passing multiple columns get_change(gettable['AFP'], gettable['Age']) |
Out[174]:
In [175]:
|
1 2 |
#check head of table gettable.head() |
Out[175]:
In [179]:
|
1 2 3 |
gettable['YoY %'] = gettable.apply(lambda x: ((x['AFP'] - x['Age'])/x['Age'])*100.0, axis=1) #lets get the year on year value by defining a lambda function #gettable['YoY %'] = get_change(gettable['AFP'], gettable['Age']) |
In [180]:
|
1 2 3 4 5 |
#round the series values to 2 decimal places #gettable.rstrip('0').rstrip('.') gettable = np.trim_zeros(gettable.round(2)) gettable |
Out[180]:
In [178]:
|
1 2 |
#run method to get some values get_change(year_subset['AFP'],year_subset['Age']) |
Out[178]:
Want more information like this?
People Who Read The Above Post Also Read This:
 Python Pandas Pivot Table Index location Percentage calculation on Two columns – XlsxWriter pt2
Python Pandas Pivot Table Index location Percentage calculation on Two columns – XlsxWriter pt2
 Python Bokeh plotting Data Exploration Visualization And Pivot Tables Analysis
Save Python Pivot Table in Excel Sheets ExcelWriter
Save Multiple Pandas DataFrames to One Single Excel Sheet Side by Side or Dowwards – XlsxWriter
Python Bokeh plotting Data Exploration Visualization And Pivot Tables Analysis
Save Python Pivot Table in Excel Sheets ExcelWriter
Save Multiple Pandas DataFrames to One Single Excel Sheet Side by Side or Dowwards – XlsxWriter