Running a Random Forest – Data Analysis and Intrepretation
Overview
My research work deals with Ghana, a country from the Gapminder dataset as has already been discussed from the beginning and progression through this course.
The variables in my observation dataset are all quantitative.
For the purposes of this assignment, I have binned my quantitative target variable, Life Expectancy (lifeexpectancy) into a 2-level binary categorical target variable. I have named this categorical target variable, lifeExpectancyCat. It has been coded as 0 = low life expectancy and 1 = high life expectancy
I have also binned 2 of the other predictor categorical variables (incomeperperson and exports) for the purpose of this assignment.
Thus these are the respective categorical end result variables of my quantitative predictor variables:
Quantitative Binary Categorical variable
incomeperperson – incomeLevelGrp
exports – exportsCatGrp
I have also added 2 more explanatory variables which is obtained
from the Gapminder website: http://www.gapminder.org/data/
to my list of variables which are used for this assignment. This is to get more explanatory variables for this Random Forest Assignment.
These new variables are:
agriculture which represents Agriculture, value added (% of GDP)
democracyscore which represents Overall polity score from the Polity IV dataset, calculated by subtracting an autocracy score from a democracy score. It is a summary measure of a country’s democratic and free nature. -10 is the lowest value, 10 the highest.
Running a Random Forest
Random forest analysis was performed to evaluate the
importance of a series of explanatory variables in predicting my binary,
categorical response variable – . The following explanatory variables were
included as possible contributors to a random forest evaluating;
income per person, exports, inflation, agriculture, and democracy score
The explanatory variable with the highest relative importance
scores was agriculture which has relative importance score of 0.4005748 followed by democracy score with a score of 0.35894682, followed by inflation with a relative importance score of 0.12744075. Then comes exports
with a score of 0.05900944. The explanatory variable with the lowest relative
importance score is income per person with a relative importance score of 0.05402819
Relative Importance Scores

The accuracy of the random forest was 95% (0.94999999999999996),
with the subsequent growing of multiple trees rather than a single tree, adding
little to the overall accuracy of the model, and suggesting that interpretation
of a single decision tree may be appropriate.
Random Forest Graph

Requesting the shape of my predictor training sample it can be seen that it has 30 observation or rows which represents 60% of our original sample and 5 explanatory variables as indicated above.

The test sample has 20 observation or rows which is 40% of
the original sample and 5 explanatory variables or columns

A Confusion Matrix was used to estimate the prediction
accuracy of my model. From the results of the Confusion Matrix, the models
accurately classified 19 of the total 20 observations included in my data set
for the classification and misclassified just 1 of the 20 observations included
in the classification process. This means the model correctly classified 95% of
the observations as having High Life Expectancy or Low Life Expectancy and
misclassified 5% of the observations in my data set.
The Confusion Matrix result can be seen below:
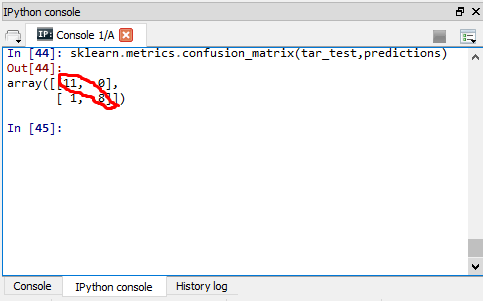
This
can be interpreted as the model having low prediction error as it correctly
classified high percentage of the observations and misclassified low percentage
of the observations in my dataset
This can further be seen by running a Test Accuracy score on my
model and the result was 0.94999999999999996 (95%) as can also be seen below:

################################
PYTHON
CODE
#################################
################################
CODE
OUTPUT
#################################