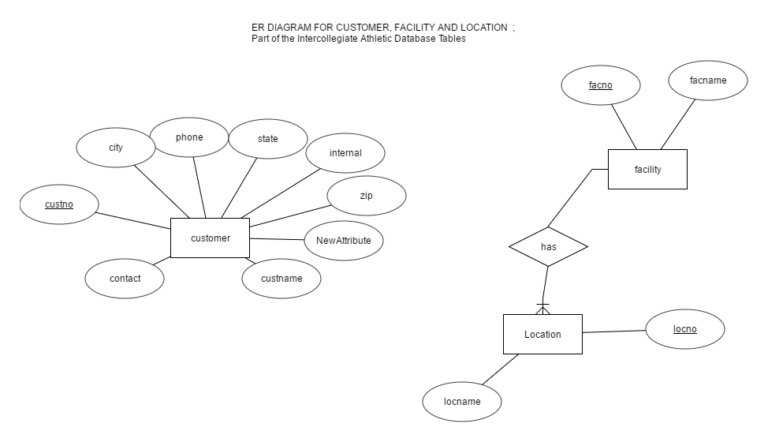
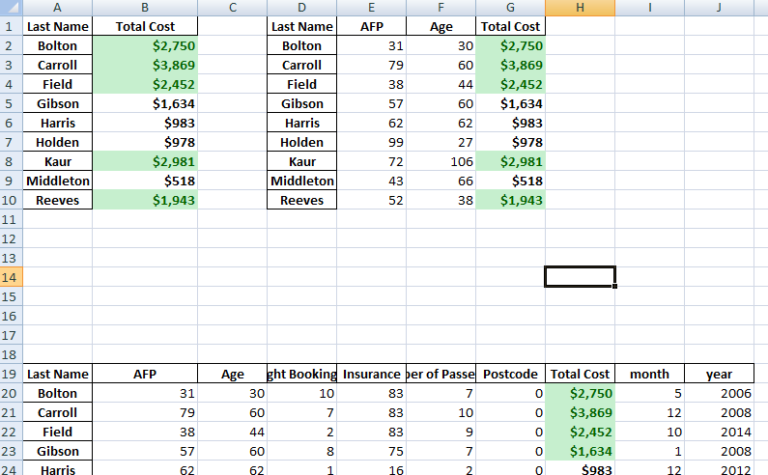
Java Python R SQL Excel Compared Similarities For Data Science and Data Analytics – The Basics
If you have ever worked with Java, Python, R, SQL, Excel and other Languages on a varied Data Science or Data Analytics projects, you will realise that all these languages have similar syntaxes, or at least, can achieve the same objective with very similar codes.
Below is a comparison and similarities of these various tools and programmes I put together for quick reference when I realised that there are some similarities between these languages languages and tools are.
Though it is not complete and exhaustive, I believe it will be of help to someone.
If you have any similarities amongst any of these languages, please leave it as a comment in the comment box I will update the table.
I would want this to help all new people who are into Data Science and Data Analytics as I wish I had something similar to this when I first started. Thank you for your contribution.
Navigating the table:
Please
- Use the search box located directly on the top right hand corner of the table to search for terms
- Use the scroll bar at the bottom of the table to see all columns
- The table has 5 columns which are Java, Python, R, SQL, Excel, Example, Description
[table id=1 /]